I Spent 5 Weeks Fixing My OpenClaw Agent Memory. Here's What Actually Works.
If you're running an OpenClaw agent, you've probably hit this wall: your agent forgets things.
Not everything. Not right away. But enough that it breaks your trust.
It forgets things you said yesterday. Forgets to send a reminder. You ask it to do something, it says it did, but it didn't. Sound familiar?
I spent 5 weeks trying to fix this. I tested 5 different memory protocols, each one more elaborate than the last. I even gave them fancy names: WAL. Working Buffer. Session Buffer. Compaction Recovery.
All of them failed.
Here's what I learned, what finally worked, and the rule I now follow for everything related to OpenClaw agent memory.
Why OpenClaw Agent Memory Fails by Default
Let me be clear: OpenClaw with its default settings is already better than anything we had before. The memory system works. It persists context across sessions. It indexes your files.
But "works" and "works reliably" are two different things.
The default setup relies on the LLM following instructions in your AGENTS.md or system prompt. Things like "always update your daily notes" or "save important context to memory files before the session ends."
The problem? LLMs don't remember to do things. They process what's in front of them right now, and that's it.
It's like asking a new intern every day: "read this 50-page manual before you start working." Day 1, he reads it. Day 5, he skips half of it. Day 10, he forgets the manual exists.
That's exactly what happened to me.
The 5 Protocols I Tried (And Why They All Failed)
Protocol 1: WAL (Write-Ahead Log)
The idea was simple: before the agent does anything, it writes what it's about to do in a log file. That way, if the session ends unexpectedly, the context is preserved.
It worked for about a week. Then the agent started skipping the write step. Why? Because writing to the log wasn't part of the actual task, so the LLM would optimize it away.
Protocol 2: Working Buffer
I created a working-buffer.md file where the agent would maintain a running summary of the current session. Active tasks, decisions made, things to remember.
Same problem. The agent would update it enthusiastically for the first few interactions, then gradually stop. By the time the session was long enough to need it, the buffer was stale.
Protocol 3: Session Buffer
More structured than the Working Buffer. Explicit sections. Clear format. Mandatory fields the agent "had to" fill in.
The agent filled in the fields — with hallucinated or generic content. "Session productive, several tasks completed." Thanks, that's useless.
Protocol 4: Compaction Recovery
When OpenClaw compacts a session (to save context window space), context gets lost. This protocol instructed the agent to check for compaction events and rebuild context from files.
The agent would check sometimes. Other times it would just start answering questions with zero context, as if nothing was wrong. No error, no warning. Just confidently wrong.
Protocol 5: Combined Protocol
I combined all four approaches. Multiple safety nets. Redundant systems.
It was too complex. The agent spent more time managing memory protocols than doing actual work. And it still failed because every single protocol depended on the same fragile thing: the LLM choosing to follow instructions.
What Finally Worked: Read the Manual
After 5 weeks of building increasingly complex behavioral protocols, I did something really old school.
I read the manual. 😂
That's when I discovered OpenClaw already had native features for most of what I was trying to do manually. I'd been so focused on making the agent smarter that I missed the tools sitting right in front of me.
Here's what actually works:
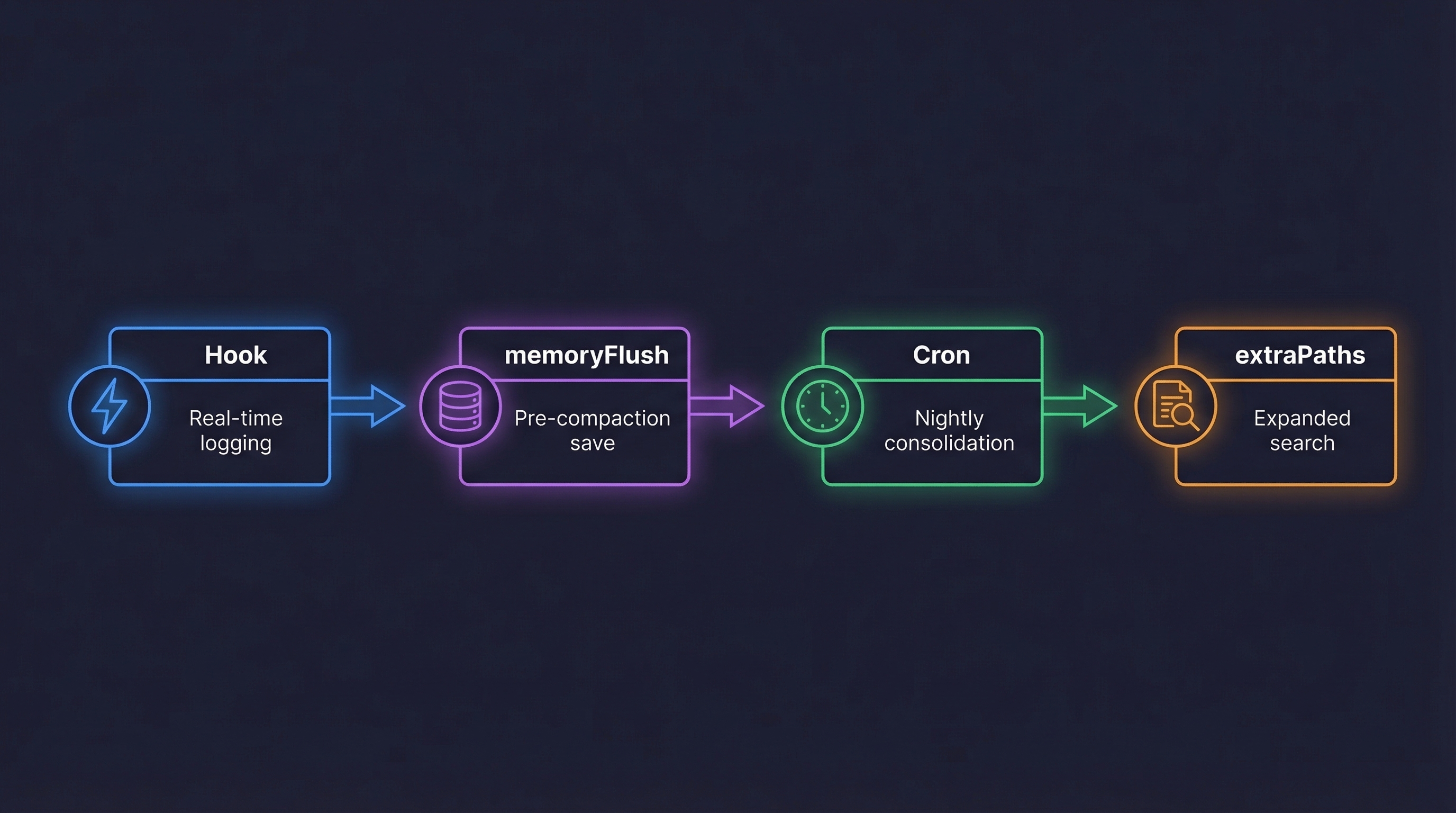
1. Hooks (Native Automation)
OpenClaw hooks run automatically on specific events — no LLM involvement. The agent doesn't need to "remember" to do anything. It just happens.
I set up a vault-buffer hook that triggers on every message (sent and received). It logs everything to a raw buffer file. Every single message, automatically. The agent doesn't even know it's happening.
No prompt instruction. No behavioral protocol. Just a hook that runs every time.
2. memoryFlush (Pre-Compaction)
Before OpenClaw compacts a session, it runs a customizable memoryFlush routine. I configured mine to read the raw buffer, extract the important stuff, and append it to my daily notes file.
This is the key: it happens before compaction, automatically. The agent doesn't need to remember to save context before the session ends. The system does it.
3. Crons (Scheduled Consolidation)
Every night at 10pm, a cron job consolidates everything. It reads the day's raw buffer, generates a structured journal entry, distributes relevant notes to the right folders, and cleans up.
Again: no LLM decision-making involved in whether this runs. It runs on a schedule. Period.
4. extraPaths (Expanded Search)
I configured memorySearch.extraPaths to index my entire notes vault. Now when the agent does a memory search, it searches across daily notes, project docs, people notes, and system documentation — not just the default memory folder.
The agent doesn't need to know where things are stored. It just searches, and the system finds it.
The Rule: Native > Hook > Script > Prompt
After this experience, I adopted a simple rule for everything I build with OpenClaw:
Native automation > Hook > Script > Prompt instruction
If OpenClaw has a native feature for it, use that. If not, write a hook that triggers automatically. If a hook doesn't fit, write a script and schedule it with a cron. Prompt instructions are the last resort, not the first.
Why? Because anything that depends on the LLM "remembering" to do something will eventually fail. Not today. Not tomorrow. But it will fail.
The moment you accept that LLMs are unreliable executors of behavioral protocols, everything clicks. Stop teaching the agent to behave. Start building systems that don't require behavior.
The Results

After implementing this approach, my agent's memory went from "hit or miss" to genuinely reliable.
- Every conversation is logged automatically (hook)
- Context survives compaction (memoryFlush)
- Daily notes are consolidated and organized (cron)
- Memory search covers everything that matters (extraPaths)
- The agent wakes up each session with rich, complete context — without needing to "remember" anything
The best part? It's simpler than any of my 5 failed protocols. Less code. Less configuration. More reliable.
What This Means for Your OpenClaw Setup
If you're struggling with agent memory, here's my advice:
- Stop writing longer prompt instructions. If your AGENTS.md has paragraphs about memory management, that's a red flag.
- Read the OpenClaw docs on hooks and memoryFlush. The features you need probably already exist.
- Use hooks for real-time logging. Don't rely on the agent to log its own conversations.
- Use memoryFlush for pre-compaction saves. This is the most underused feature in OpenClaw.
- Use crons for periodic consolidation. Daily wrap-ups, journal generation, cleanup — schedule it, don't hope for it.
- Configure extraPaths. Make sure memory search covers all your important files, not just the defaults.
If your workflow depends on an AI agent "behaving properly", you're building on sand.
Build the system. Let the agent think.